
Decoding the Beat: Predicting Music Genres with Audio Features
As a business analyst at UT Austin, I specialize in data science, utilizing SQL and Python to develop solutions. My focus on predictive modeling and AI prepares me for impactful roles in healthcare and finance, aiming to enhance efficiency through big data insights and innovative strategies.
Rohan Giri
5/8/20244 min read


Abstract
In the age of music streaming and AI-powered tools, understanding what makes a song belong to a specific genre is both an art and a science. Our project explores this intersection by developing machine learning models that classify music tracks into their respective genres using audio features such as tempo, harmony, and other attributes extracted with Librosa. By analyzing the unique characteristics embedded within audio files, the model aims to distinguish between ten distinct genres, offering a fascinating glimpse into the relationship between sound and classification.
To achieve this, we employ a combination of traditional machine learning algorithms and cutting-edge deep learning techniques, rigorously testing our approach on a diverse dataset of music tracks. Evaluation focuses on accuracy and genre assignment performance, ensuring robust results that reflect real-world complexity. This exploration not only sheds light on the intricate connection between audio features and genre identification but also highlights the potential of AI in transforming how we experience and organize music.
Introduction
Music has a unique ability to evoke emotions, connect cultures, and transcend boundaries, yet the underlying characteristics that define its genres often go unnoticed by the casual listener. From the rhythm of a jazz track to the intricate harmonies of classical compositions, each genre possesses distinct audio features that make it recognizable. In our project, we aim to harness these features to develop a machine learning model capable of accurately classifying music tracks into their respective genres. Using tools like Librosa to extract features such as tempo and harmony, the model will analyze the unique characteristics of audio files to distinguish between ten diverse genres. This exploration not only enhances our understanding of audio signals but also showcases the power of artificial intelligence in bridging the gap between data and artistic expression.
The challenge of genre classification has been addressed in various ways, as seen in related works that utilize datasets like the GTZAN and tools like CNNs for audio classification. Our approach builds on these foundations, leveraging advanced techniques such as feature extraction and deep learning models like CNNs. By combining traditional machine learning algorithms with deep learning architectures, our project explores the nuances of audio data while addressing common challenges like data imbalance and feature redundancy. Beyond genre classification, the insights gained from this project hold potential for applications in music recommendation systems, playlist curation, and personalized listening experiences, paving the way for more intuitive interactions with music platforms.
Data Discovery and Pre-Processing
Relevant Characteristics
The dataset used for this project includes audio files from the GTZAN dataset, hosted on Kaggle, which contains 100 30-second audio clips for each of 10 music genres: Blues, Classical, Country, Disco, Hip-hop, Jazz, Metal, Pop, Reggae, and Rock.
Sources and Methods of Acquisition
The primary dataset was sourced from Kaggle, including metadata and features precomputed using the Python library, Librosa. To expand the dataset and improve classification relevance for modern music, additional data was scraped from YouTube, focusing on 20 new songs per genre from 2002 onward. This data acquisition involved scraping video links, converting audio to .wav format, and processing the files to ensure compatibility with the rest of the dataset. All features are recalculated using Librosa to maintain consistency and ensure a comprehensive set of audio characteristics.
Feature Engineering and Selection
The feature set includes detailed audio characteristics extracted using Librosa, such as:
Chroma Features: Chroma_stft, Chroma_cqt, and Chroma_cens, representing pitch classes and tonal progression.
Spectral Features: Spectral centroid, spectral bandwidth, and spectral rolloff, describing the brightness and frequency distribution of the sound.
Temporal Features: Zero-crossing rate, RMS (loudness), harmony, and percussive elements, capturing rhythmic and temporal aspects.
MFCCs: 20 Mel-frequency cepstral coefficients to describe timbre.
Tempo: Capturing the pace of music. These features ensure comprehensive coverage of the audio’s tonal, rhythmic, and spectral dimensions. During modeling, feature selection techniques, such as correlation analysis and feature importance in tree-based models, will be used to refine the feature set.
We chose this method of feature extraction to gather as much information on the sound clips as possible. Each of these features are extremely informative and useful in signal processing and audio classification.
Data Splitting and Exploration
To prepare the dataset for training, validation, and testing, all samples from the same 30-second clip are held within a single subset to prevent data leakage. The dataset is split in a stratified manner to ensure equal representation of genres:
Training Set: 80% of the data.
Validation Set: 20% of the data.
Originally we set the data split at 70/30 but due to the amount of data that we had this was not quite sufficient to train the models to their best ability. Giving models more data drastically improved results and in the future gathering even more data would be a better idea.
Visualizing Audio Features
The Chroma STFT is a feature representation that uses a Short-Time Fourier Transform (STFT) to extract energy distribution over the 12 possible pitches
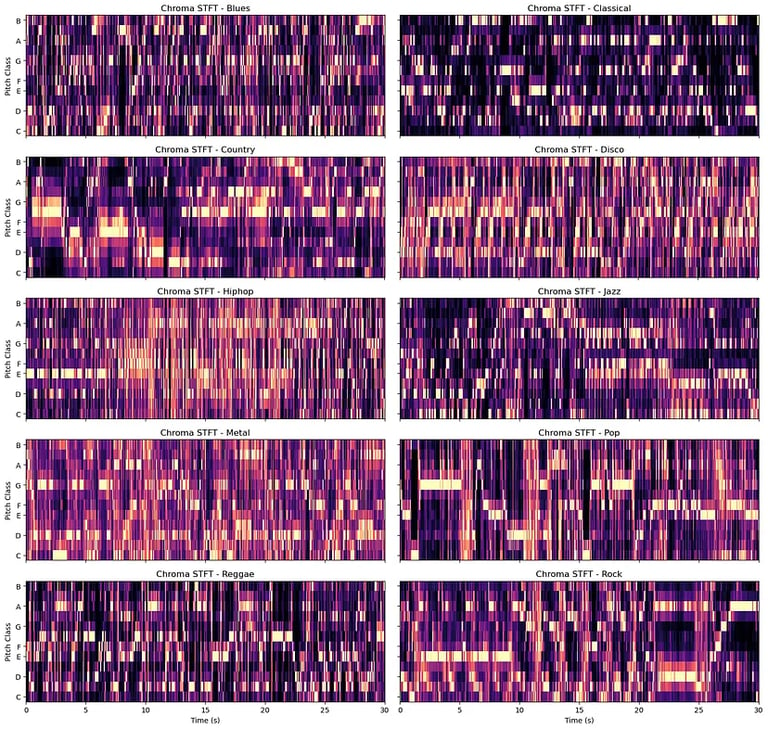
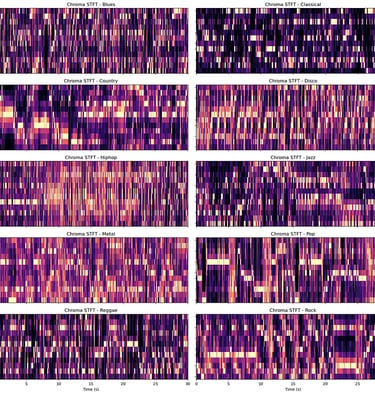
The Spectral Centroid measures the “tonal character” or brightness in the sound over time. A higher spectral frequency represents a brighter sound, while a lower spectral frequency represents a darker sound.

